
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- C++
- 낙관적 업데이트
- 최소공배수
- css
- 동기
- 유클리드 호제법
- 파이썬
- prototype 프로퍼티
- dp
- 한글 입력 시 이벤트 두 번 발생
- 백트래킹
- 메타버스
- 자바스크립트
- 알고리즘
- 9610
- 프로그래밍
- 동적 계획법
- 한글이 두 번 입력됨
- Tanstack Query
- backtracking
- 백준 9610번 파이썬 문제 풀이
- __proto__ 접근자 프로퍼티
- javascript
- 2522
- python
- 비동기
- 백준
- 시간
- 함수 객체의 프로퍼티
- float: right
- Today
- Total
염딩코
[Algorithm] LCS: Longest Common Substring와 Longest Common Subsequence 본문
[Algorithm] LCS: Longest Common Substring와 Longest Common Subsequence
johnyeom 2023. 9. 25. 16:33Longest Common Substring 과 Longest Common Subsequence 란?
LCS는 주로 최장 공통 부분 수열(Longest Common Subsequence)을 말합니다만,
최장 공통 문자열(Longest Common Substring)을 말하기도 합니다.
문자열 ABCDEF와 GBCDFE를 이용하여 차이점을 예시로 들어보면

해당 예시에서 최장 공통 부분수열(Longest Common Subsequence)은 BCDF, BCDE가 될 수 있습니다.
부분수열이기 때문에 문자 사이를 건너뛰어 공통되면서 가장 긴 부분 문자열을 찾으면 됩니다.
최장 공통 문자열(Longest Common Substring)은 BCD입니다.
부분문자열이 아니기 때문에 한번에 이어져있는 문자열만 가능합니다.
최장 공통 문자열(Longest Common Substring)
최장 공통 부분수열(Longest Common Subsequence)을 구하기 전에 최장 공통 문자열(Longest Common Substring)을 먼저 보도록 하겠습니다.
해당 과정이 더 쉽고, 최장 공통 부분수열(Longest Common Subsequence)을 구하는데 사용되기 때문에 먼저 알아보겠습니다.
점화식
if(i === 0 || j === 0) // 경계값 설정
LCS[i][j] = 0;
else if(string_A[i] === string_B[j])
LCS[i][j] = LCS[i-1][j-1] + 1;
else
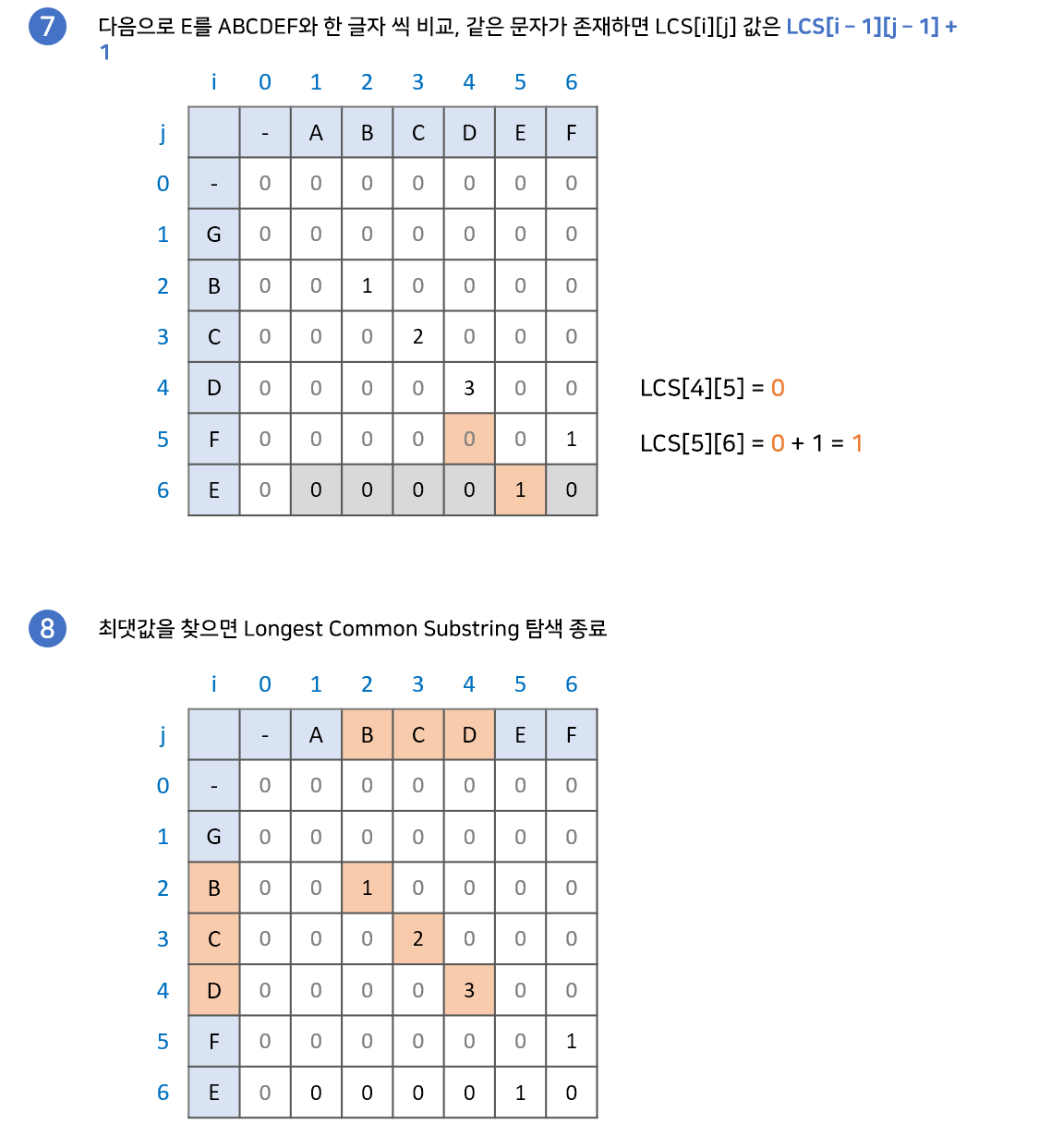
LCS[i][j] = 0;최장 공통 문자열의 점화식을 코드로 작성해보았습니다. LCS라는 2차원 배열을 이용하여 두 문자열을 행, 열에 매칭합니다.
편의상 i, j가 0일때는 모두 0을 넣어줘 경계값을 설정합니다. 이후 i, j가 1이상일 때부터 검사를 시작합니다.
검사 순서는 다음과 같습니다.
1. 문자열 A, 문자열 B의 한 글자씩 비교해봅니다.
2. 두 문자가 다르다면 LCS[i][j] = 0
3. 두 문자가 같다면 LCS[i][j] = LCS[i-1][j-1] + 1
4. 위 과정을 반복합니다.
위 과정이 성립하는 이유는 공통 문자열은 연속되야 하기 때문입니다.
현재 두 문자가 같을때, 두 문자의 앞 글자까지가 공통 문자열이라면 계속 공통 문자열이 이어질 것이고, 아니라면 본인부터 다시 공통 문자열을 만들어 가게 될 것입니다.
아래 예시를 통해 직관적으로 확인할 수 있습니다.
구현과정


최장 공통 부분수열(Longest Common Subsequence)
점화식
if(i === 0 || j === 0) // 경계값 설정
LCS[i][j] = 0;
else if(string_A[i] === string_B[j])
LCS[i][j] = LCS[i - 1][j - 1] + 1;
else
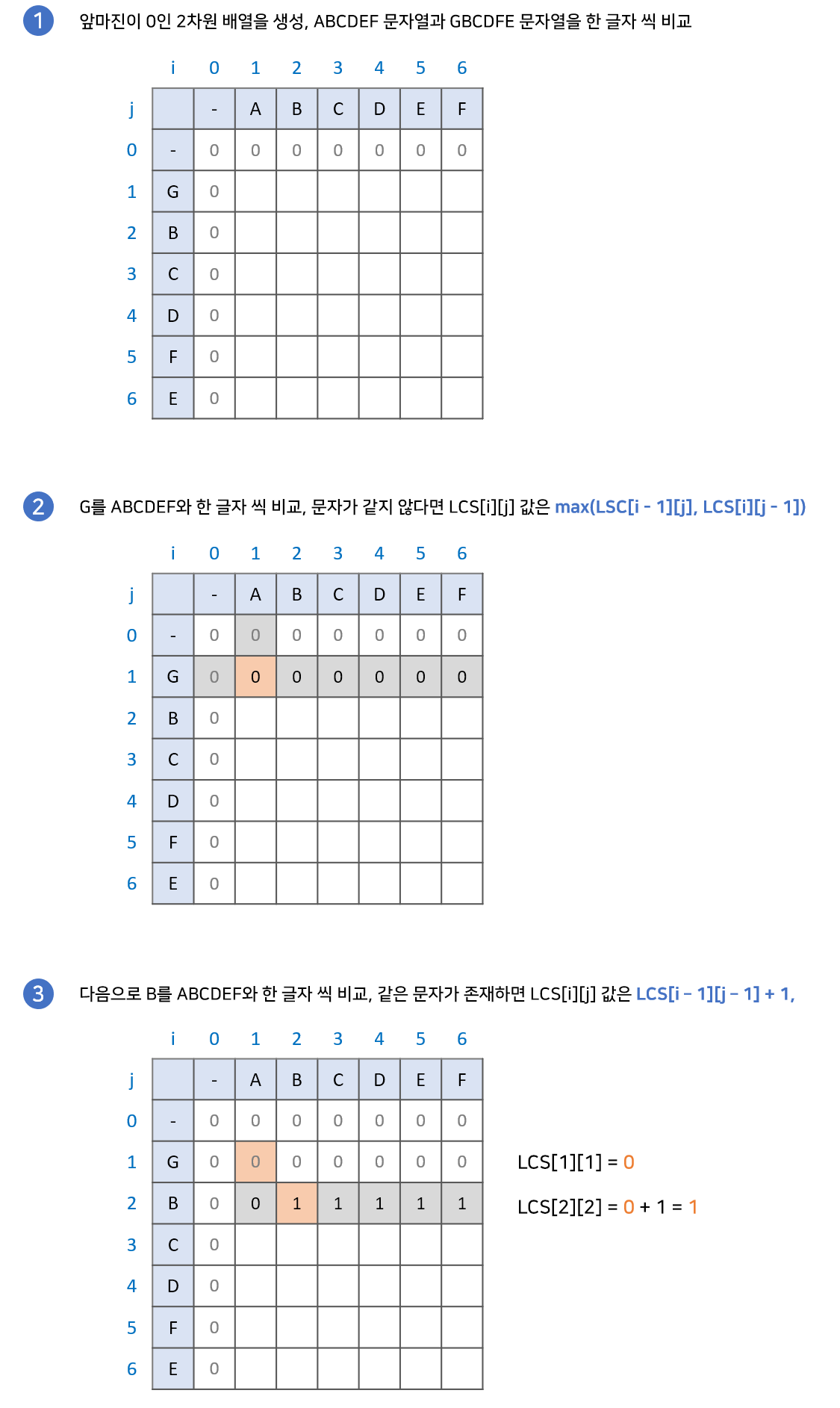
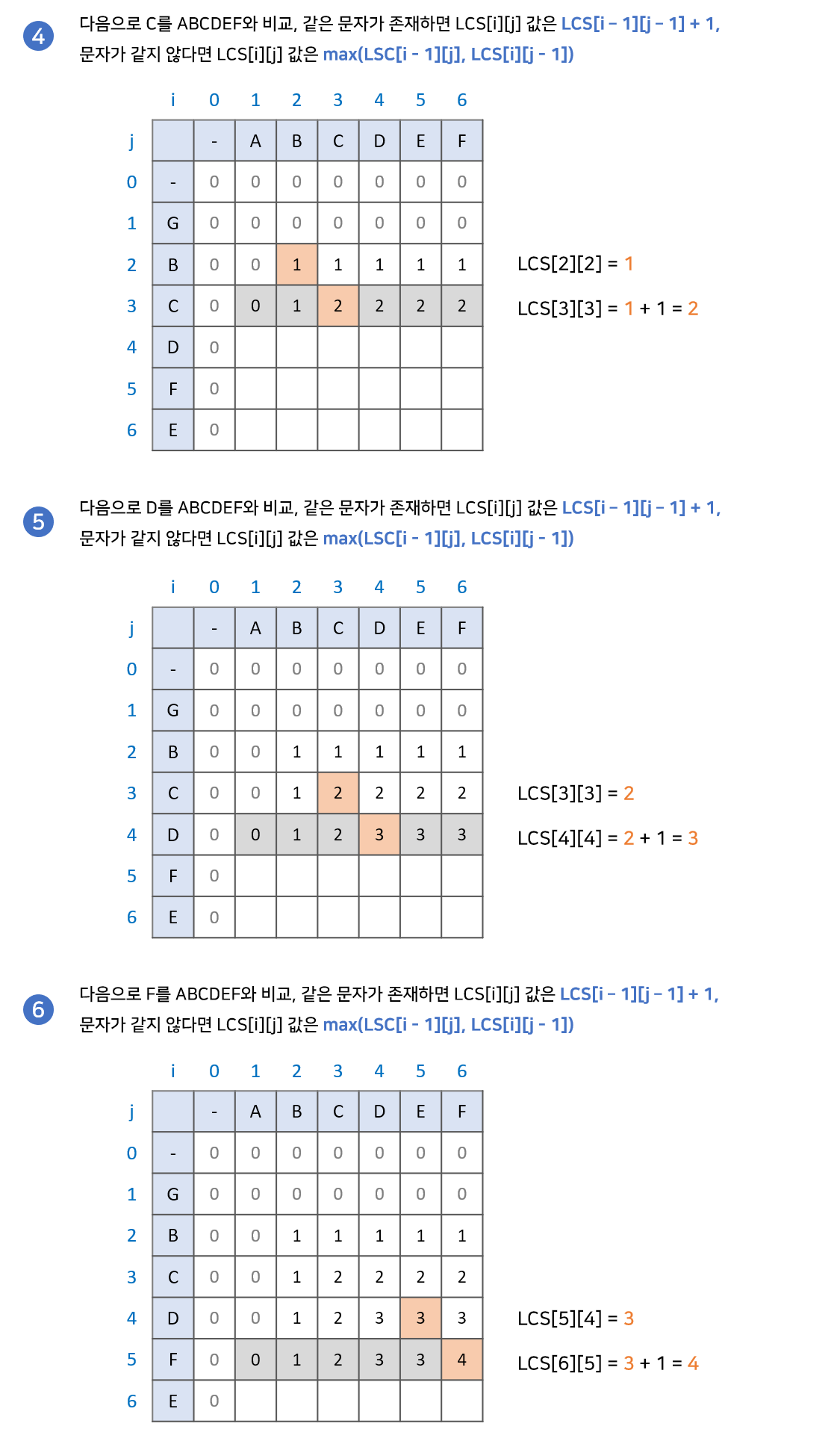
LCS[i][j] = Math.max(LCS[i - 1][j], LCS[i][j - 1]);최장 공통 부분수열의 점화식을 코드로 작성해보았습니다.
위와 마찬가지로 LCS라는 2차원 배열에 매칭하고 마진값을 설정한 후 검사합니다.
검사 순서는 다음과 같습니다.
1. 문자열A, 문자열B의 한글자씩 비교해봅니다.
2. 두 문자가 다르다면 LCS[i - 1][j]와 LCS[i][j - 1] 중에 큰 값을 표시합니다.
3. 두 문자가 같다면 LCS[i - 1][j - 1] 값을 찾아 +1 합니다.
4. 위 과정을 반복합니다.
최장 공통 문자열을 구하는 과정과 다른부분은 비교하는 두 문자가 다를 때 입니다. 비교하는 두 문자가 같을 때는 같은 과정을 보여줍니다. 왜 어떤 부분은 다른 로직을, 어떤부분은 같은 로직을 사용하는지 상세히 살펴보겠습니다.
LCS[i - 1][j]와 LCS[i][j - 1]는 어떤 의미인가?
부분수열은 연속된 값이 아닙니다.
그렇기 때문에 현재의 문자를 비교하는 과정 이전의 최대 공통 부분수열은 계속해서 유지됩니다.
'현재의 문자를 비교하는 과정' 이전의 과정이 바로 LCS[i - 1][j]와 LCS[i][j - 1]가 됩니다.

문자열 AB와 GBC를 비교(위 그림의 초록색 부분)하는 과정을 예로 들어보겠습니다.
AB와 GBC의 최대 공통 부분수열이 B라는 것을 알기 위해서는 문자열 A와 GBC를 비교하는 과정, 문자열 AB와 GB를 비교하는 과정이 필요합니다.
문자열 AB와 GB의 비교 과정에서 최대 공통 부분수열이 B임을 확인했기 때문에 문자열 AB와 GBC의 최대 공통 부분수열 역시 B가 되는 것입니다.

왜 문자가 같으면 LCS[i][j] = LCS[i - 1][j - 1] + 1인가?
최대 공통 문자열을 구할 때 비교하는 문자가 같으면, LCS[i][j] = LCS[i - 1][j - 1] + 1의 과정을 거쳤습니다.
이 과정이 어떻게 최대 공통 부분수열에도 똑같이 적용될까요? 부분수열이 연속될 필요가 없음을 위 과정에서 여러번 보았습니다.
그렇다면 답은 간단합니다. 두 문자가 같은 상황이 오면 지금까지의 최대 공통 부분수열에 1을 더해주는 것 입니다.
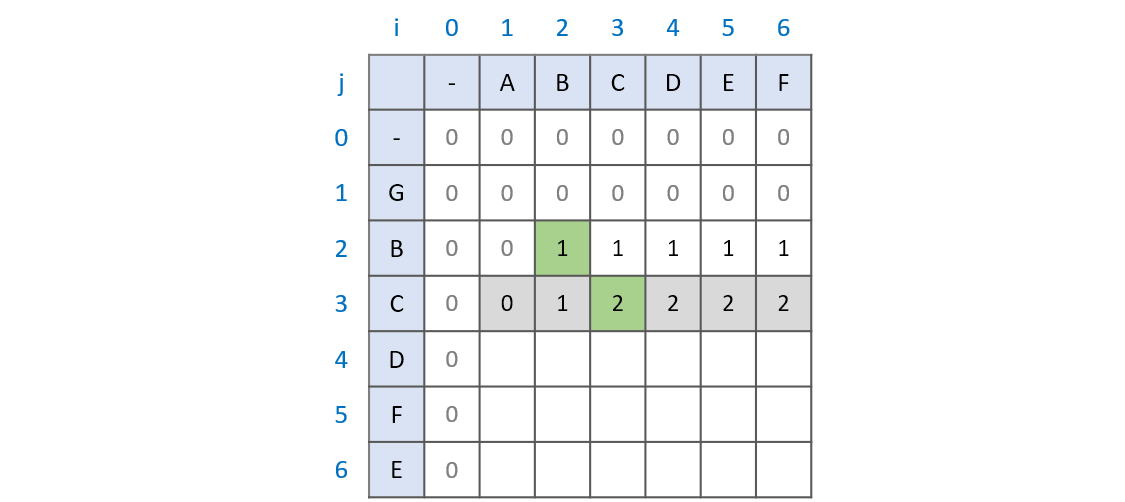
문자열 ABC와 GBC를 비교(위 그림의 초록색 부분)하는 과정을 예로 들어보겠습니다.
LCS 배열은 LCS[i - 1][j]와 LCS[i][j - 1]의 비교를 통해 언제나 본인까지의 최대 공통 부분수열 값을 가지고 있습니다.
문자열 AB와 GB를 비교할때와 문자열 ABC와 GBC를 비교할 때 달라진 점은 두 문자열 모두에 C가 추가된 점입니다.
그렇기 때문에 기존의 최대 공통 부분수열인 B에 C를 더한 BC가 최대 공통 부분수열이 되는 것입니다.

구현과정

최장 공통 부분수열(Longest Common Subsequence) 찾기
위에서 LCS 구현과정을 통해 LCS 배열을 만들며 LCS의 길이를 알았습니다.
이제 만든 LCS 배열을 이용해 최장 공통 부분수열의 값을 찾아보겠습니다.
(경우에 따라 여러가지 답이 나올 수 있기 때문에 아래 예시는 한가지 경우만을 보겠습니다.)
검사순서는 다음과 같습니다.
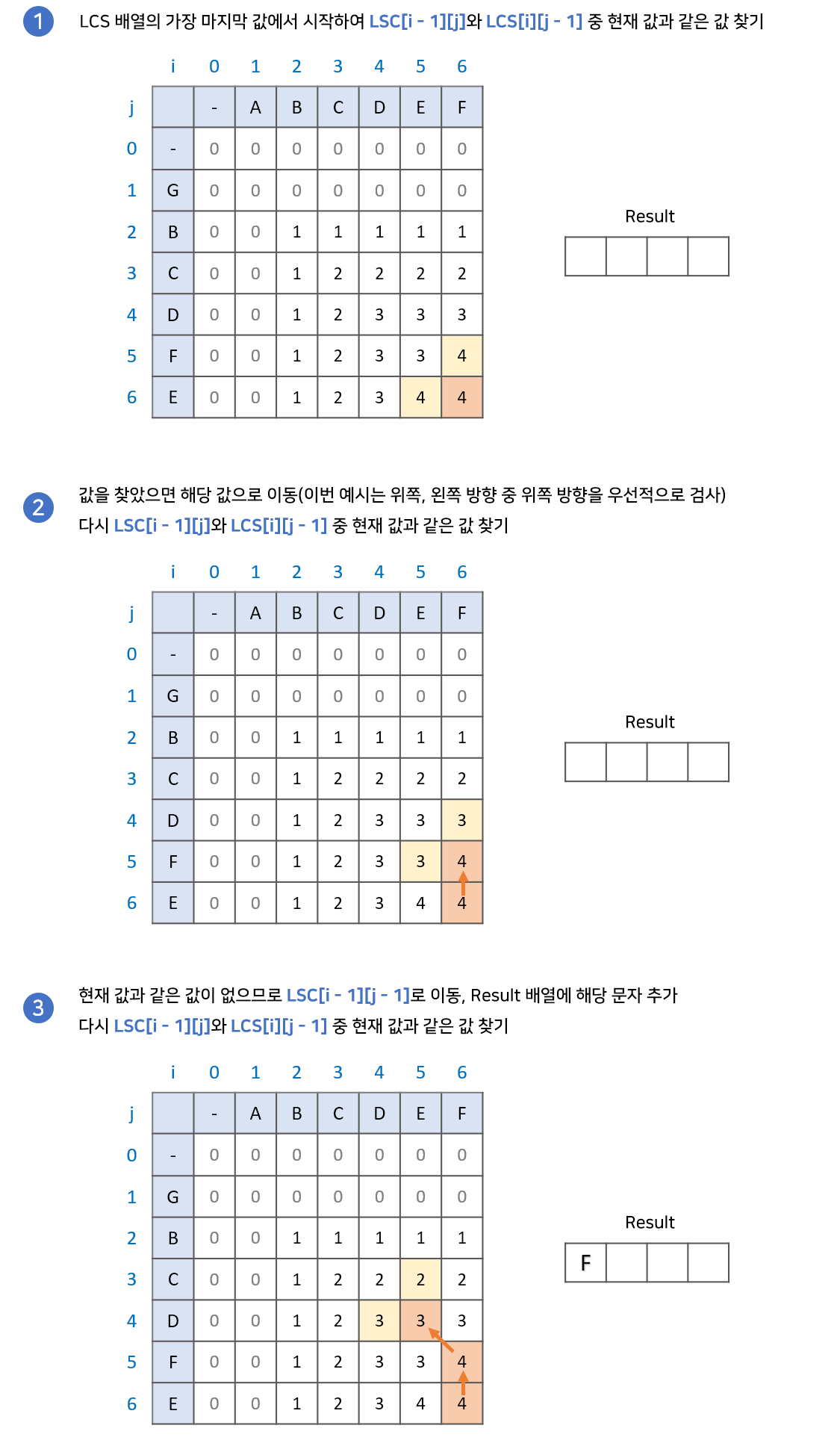
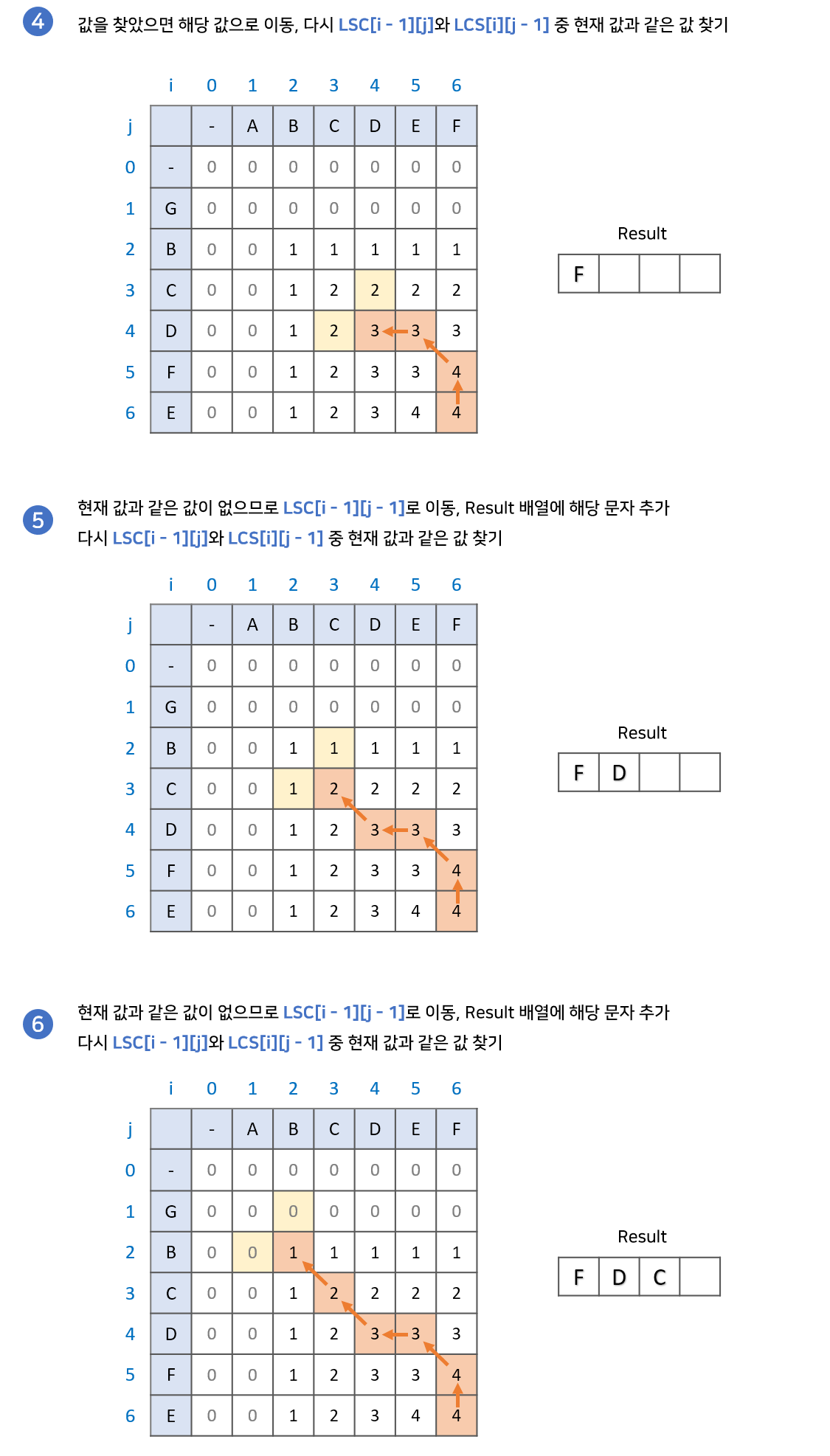
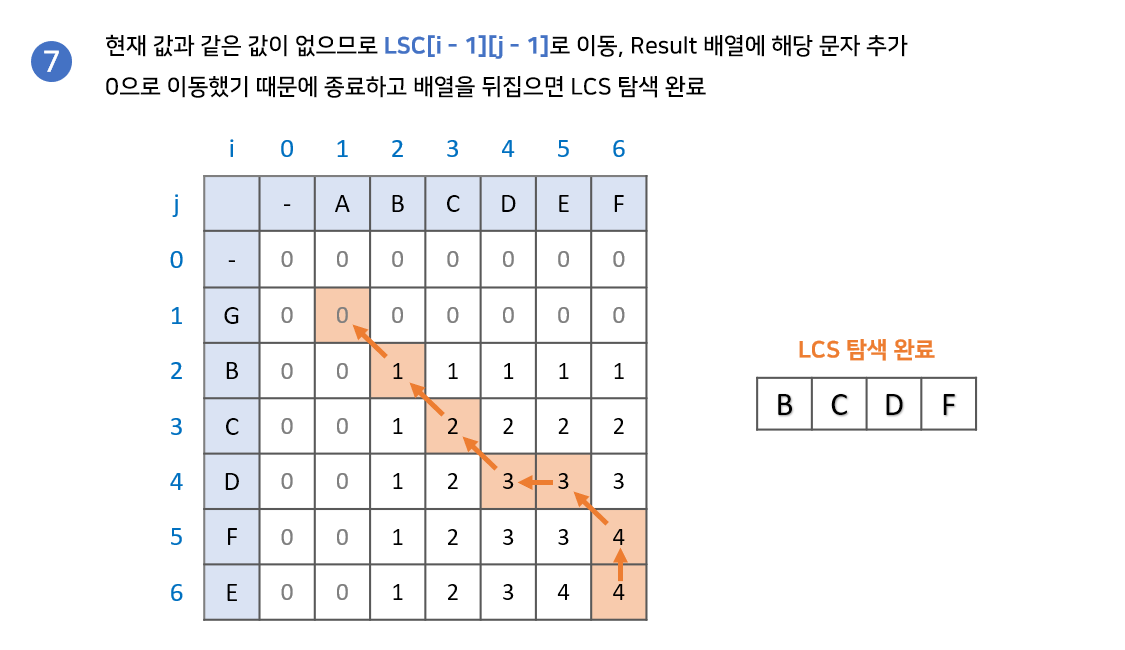
1. LCS 배열의 가장 마지막 값에서 시작합니다. 결과값을 저장할 result 배열을 준비합니다.
2. LCS[i - 1][j]와 LCS[i][j - 1] 중 현재 값과 같은 값을 찾습니다.
2-1. 만약 같은 값이 있다면, 해당 값으로 이동합니다.
2-2. 만약 같은 값이 없다면, result배열에 해당 문자를 넣고 LCS[i -1][j - 1]로 이동합니다.
3. 2번 과정을 반복하다가 0으로 이동하게 되면 종료합니다. result 배열의 역순이 LCS 입니다.
구현과정
참고 및 이미지 출처: https://velog.io/@emplam27
'TIL' 카테고리의 다른 글
| 캐시(cache)란 무엇인가? (0) | 2023.06.08 |
|---|---|
| 가상 메모리(Virtual memory)란? (0) | 2023.06.08 |
| [C#] get, set 이란? (0) | 2023.05.27 |
| [Algorithm] Backtracking이란? (0) | 2023.05.19 |
| [Algorithm] 허프만 코드(Huffman code) (0) | 2023.05.18 |